
Microsoftは2026年4月2日、自社開発の音声認識AIモデル「MAI-Transcribe-1」のパブリックプレビューを開始した。同時に音声生成モデル「MAI-Voice-1」、テキスト→画像生成モデル「MAI-Image-2」の3モデルをMicrosoft Foundryおよびデベロッパー向けのMAI Playgroundで公開した。
MAI-Transcribe-1は主要25言語に対応した音声認識(Speech-to-Text)モデルだ。業界標準ベンチマーク「FLEURS」での評価では、単語誤り率(WER)3.8%を達成し、OpenAI Whisper large-v3、GPT-Transcribe、Google Gemini 3.1 Flash-Liteを上回り、対応25言語中11言語でトップの精度を記録した。GPU処理コストは競合製品比で約50%削減されており、エンタープライズ向けにコスト効率が高い設計となっている。
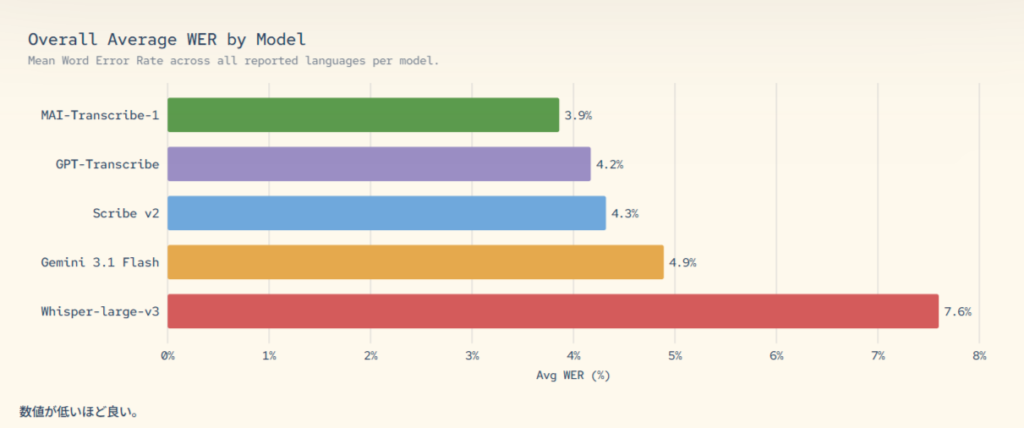
同モデルはバックグラウンドノイズ、低品質音声、複数人が同時に話す状況など、現実の過酷な収録環境での利用を想定して構築されている。ビジネス向けの主な活用シーンとしては、会議のリアルタイム文字起こし、コールセンターの通話分析、動画字幕の自動生成、アクセシビリティ対応、音声エージェント構築などが挙げられる。
音声生成モデルMAI-Voice-1は1枚のGPUで60秒分の表現豊かな音声を1秒未満で生成できる。MAI-Image-2はテキストから画像を生成するモデルで、Arena.aiの画像モデルリーダーボードで第3位にデビューした。Microsoftは、これらのモデルがすでにCopilot、Bing、PowerPointなどの自社製品に組み込まれていると説明している。

