
AI音声技術のグローバルリーダーであるElevenLabs(イレブンラボ)は1月20日、音声認識(STT)の最新モデル「Scribe V2」を発表した。字幕・キャプション制作や大規模文字起こしに最適化された次世代モデルとして、長尺・複雑な音声でも精度と安定性を維持する設計となっている。

Scribe V2は90以上の言語に対応し、業界標準ベンチマークにおいて最低水準のWER(単語誤り率)を記録。日本語モデルにおいても他社主要モデルを凌駕する認識精度を実証している。

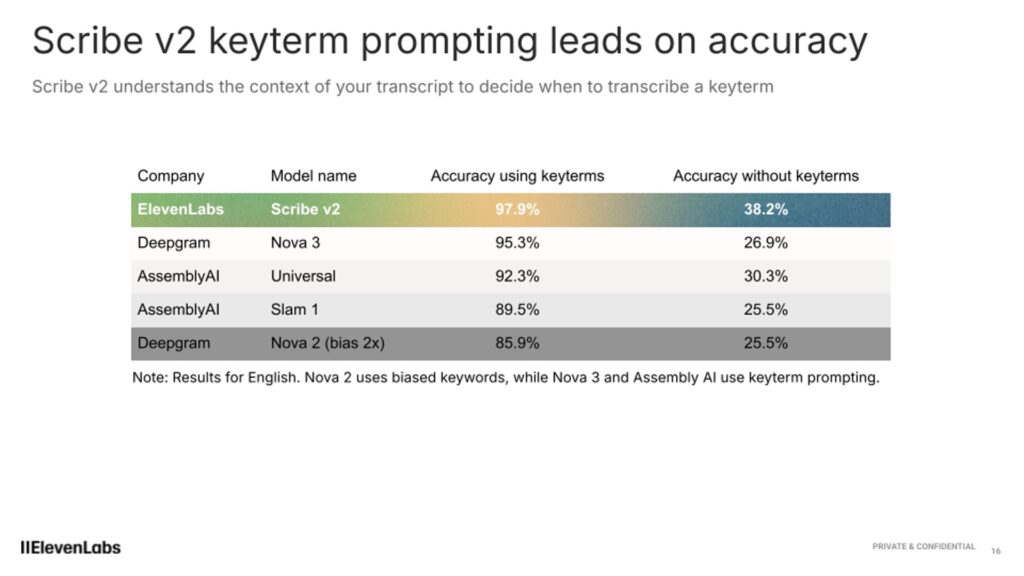
主要機能として、最大100個の単語・フレーズを指定できる「Keyterm Prompting」を搭載。社内用語や製品名、医療・法律・技術用語など専門性の高い領域での精度向上を実現する。また「Entity Detection」機能では、個人情報や決済情報、医療データなど最大56カテゴリを自動検知し、マスキングとタイムスタンプ付与が可能だ。

同一音声ファイル内で言語が切り替わるケースでも自動判定して文字起こしを行うほか、話者分離、単語レベルのタイムスタンプ、笑い声や拍手などの音イベントタグ機能も標準搭載される。
セキュリティ面では、SOC 2、ISO 27001、PCI DSS Level 1、HIPAA、GDPRなどの要件に対応。Scribe V2は本日より、同社のAPIおよびプロダクトから利用可能である。

