
米OpenAIは2026年5月7日、リアルタイム音声AIモデルの新世代3モデルをAPIに追加したと発表した。音声による会話・翻訳・文字起こしをリアルタイムで実現するこれらのモデルにより、開発者はより自然で高度な音声アプリを構築できるようになる。
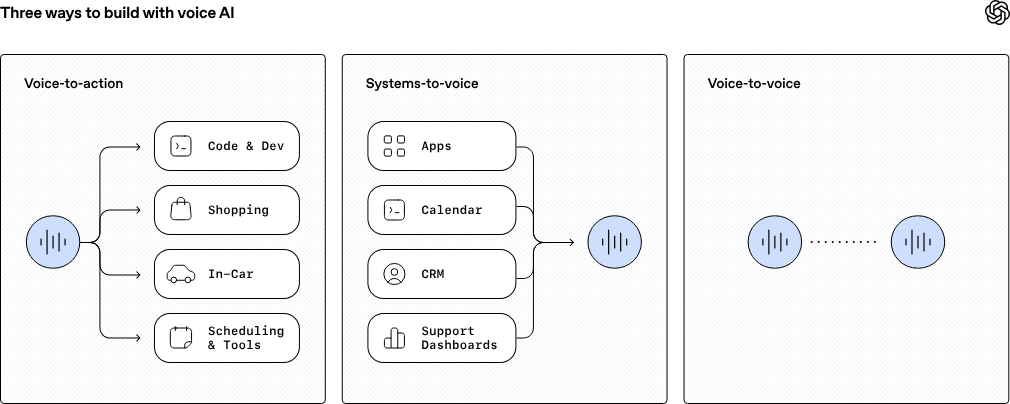
発表された3モデルは次のとおりである。「GPT-Realtime-2」はGPT-5クラスの推論能力を備えた同社初の音声モデルで、複雑なリクエストへの対応や会話の自然な継続が可能。「GPT-Realtime-Translate」は70以上の入力言語から13の出力言語へリアルタイムで翻訳するライブ翻訳モデル。「GPT-Realtime-Whisper」は話し手の発話に合わせてリアルタイムで文字起こしを行うストリーミング音声認識モデルである。
GPT-Realtime-2は従来モデル(GPT-Realtime-1.5)と比較して、音声知性の評価指標Big Bench Audioで15.2%、会話型指示追従の評価指標Audio MultiChallengeで13.8%それぞれスコアが向上している。推論処理中も会話を途切れさせずに継続できる設計が特徴だ。
料金体系はGPT-Realtime-2が音声入力トークンあたり32ドル/100万トークン、音声出力64ドル/100万トークン。GPT-Realtime-TranslateおよびGPT-Realtime-Whisperは分あたり課金で、それぞれ0.034ドル/分、0.017ドル/分に設定されている。すべてのモデルはRealtime APIで利用可能で、OpenAIのPlaygroundでも試用できる。
同社によると、すでにZillowがGPT-Realtime-2を複雑な音声対応に活用し、通話成功率とコンプライアンスの堅牢性が大幅に向上したと報告している。またDeutsche TelekomはGPT-Realtime-Translateを活用した多言語顧客対応の実証に取り組んでいる。安全対策として有害コンテンツ検知時に会話を自動停止するクラシファイアーも実装されている。
https://openai.com/index/advancing-voice-intelligence-with-new-models-in-the-api/

