
GoogleのResearch部門は2026年3月24日、大規模言語モデル(LLM)のメモリ消費を大幅に削減する新たな圧縮アルゴリズム「TurboQuant」を発表した。訓練やファインチューニングを必要とせず、モデルの精度を損なうことなくKV(キーバリュー)キャッシュのメモリ使用量を最大6分の1に削減できるとしており、ICLR 2026での発表も予定されている。
LLMの推論処理において、KVキャッシュはトークン生成のたびに過去の計算結果を保存する作業メモリとして機能する。コンテキスト長が増加するにつれてKVキャッシュのサイズも比例して膨張し、メモリのボトルネックが深刻化する課題があった。従来のベクトル量子化手法ではデータ圧縮が可能だが、量子化定数の保存に伴うメモリオーバーヘッドが1〜2ビット発生し、圧縮効果が部分的に相殺されるという問題があった。
TurboQuantは2段階のアプローチでこの課題を解決する。第1段階の「PolarQuant」では、データベクトルをランダム回転させて幾何学的構造を単純化し、効率的な量子化を可能にする。第2段階では「Quantized Johnson-Lindenstrauss(QJL)」アルゴリズムを用いて残差誤差を処理し、アテンション計算における内積推定のバイアスを除去する。この組み合わせにより、量子化定数のオーバーヘッドをゼロに抑えながら高精度な圧縮を実現する。
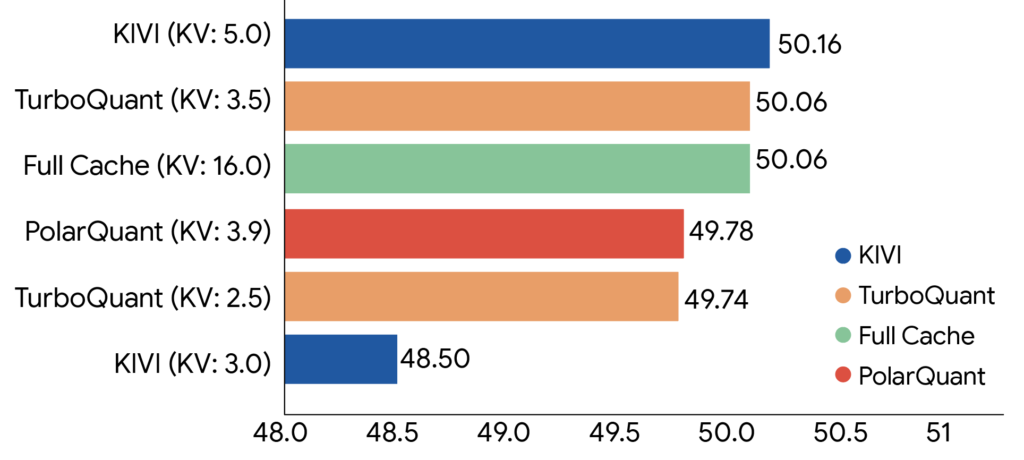
ベンチマーク評価ではGemmaおよびMistralモデルを用いてLongBench、Needle In A Haystack、ZeroSCROLLS、RULER、L-Evalの各テストを実施した。3ビット量子化においてNeedle In A Haystackタスクで完全な精度を維持しつつ、KVキャッシュメモリを最低6分の1に削減することを確認した。また、NVIDIA H100 GPU上での実験では、4ビットのTurboQuantが32ビット非量子化キーと比較してアテンションロジット計算で最大8倍の処理速度向上を達成した。
Googleは同技術がGeminiなどの大規模モデルにおけるKVキャッシュボトルネックの解消に有効と説明しており、ベクトル検索エンジンの高速化にも応用できるとしている。公式のオープンソースコード公開は2026年第2四半期を予定している。本研究はGoogleリサーチの研究科学者Amir Zandieh氏とVP・Google FellowのVahab Mirrokni氏が共同で執筆した。
https://research.google/blog/turboquant-redefining-ai-efficiency-with-extreme-compression/

