
NTTが、私たちの話し方や声を再現する最先端技術を発表しました。
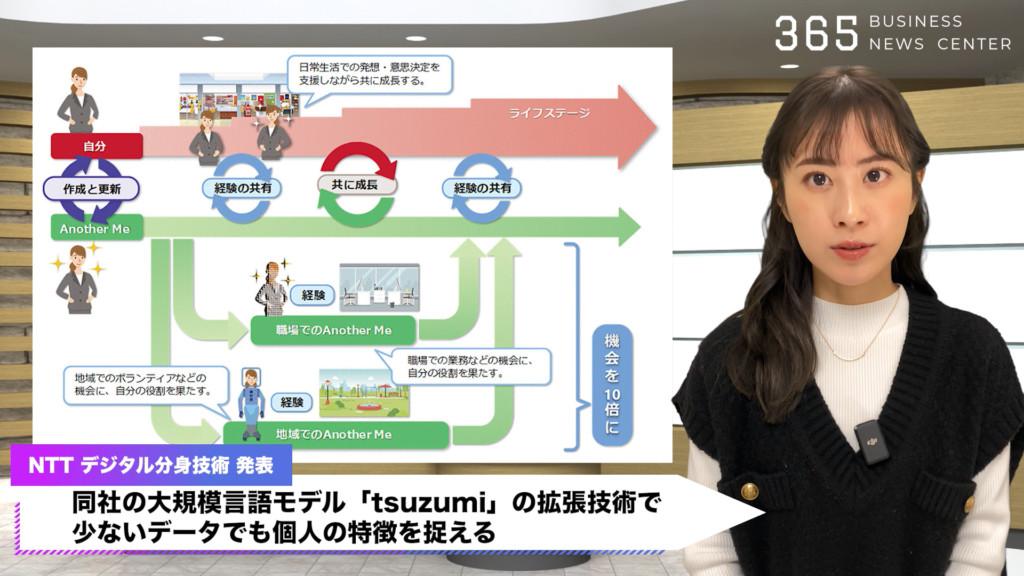
同社の大規模言語モデル「tsuzumi」の拡張技術で、少ないデータでも個人の特徴を捉える「個人性再現対話技術」と、声色を真似る「Zero/Few-shot音声合成技術」。
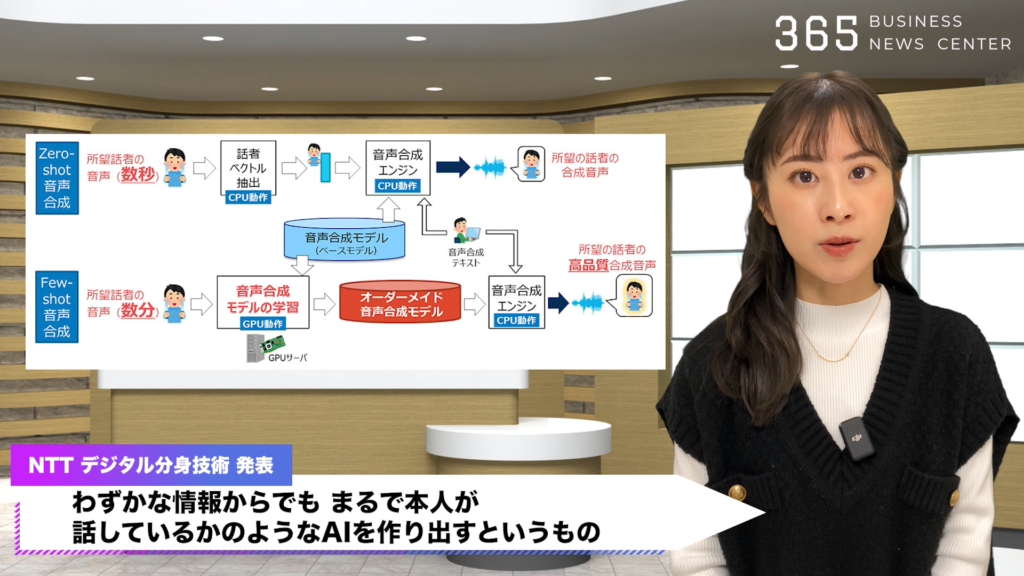
わずかな情報からでも、まるで本人が話しているかのようなAIを作り出すというもの。
これにより、
本人のデジタル分身を低コストで生成することが可能になります。
音声合成技術では、数秒から数分の音声データを使って、個人の声色を反映した音声を作り出します。

これは、声を失った人々にも役立つ可能性もあるとのこと。
これからのデジタル社会で私たちのコミュニケーションがAI技術の研究でどのように変わるのか、注目されています。

